Microtask crowdsourcing is the practice of breaking down an overarching task to be performed into numerous, small, and quick tasks that are distributed to an unknown, large set of workers. Microtask crowdsourcing has shown tremendous potential in other disciplines, but with only a handful of approaches explored to date in software engineering, its potential in our field remains unclear.
We explore how microtask crowdsourcing might serve as a means to locate fault in software, more specifically, we are interested in studying the effectiveness, cost, and speed of a crowd of workers to correctly locate known faults in small code fragments taken from real world software. We have been running large scale experiments through Mechanical Turk, where we can collect the answers from hundreds of workers to a pre-determined set of template questions applied to the code fragments. Questions are asked multiple times and workers answer multiple different questions. Our findings show that it is possible for a crowd to correctly distinguish questions that cover lines of code containing a fault from those that do not.
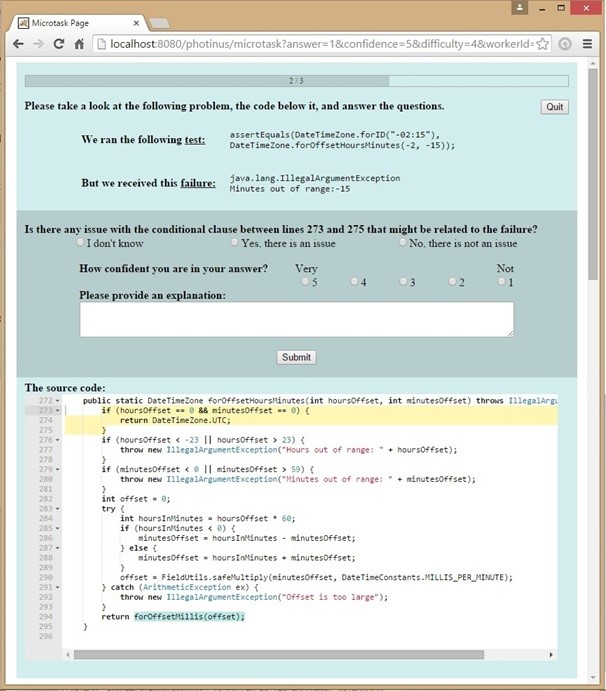
The image below shows an example of a fault localization task. In this task a worker receives information about a software failure and the unit test that exposed the failure. The worker also receives the source code of the Java method that failed the unit test. The task basically consists of answering a question about the possible relation between a code fragment and the failure.
Highlights
We have so far identified a set of design concerns in crowdsourcing fault localization (see below). We are looking for design alternatives that contribute to locate faults efficiently, cost-effectively, and fast.
What to ask questions about? – We currently ask questions about program statements (e.g., method invocations, loops, conditionals, and variables). Which questions should we ask in order to locate more complex bugs, such as bugs involving null pointers or wrong class type? What type of support and information workers need to answer these types of questions?
How to predict fault locations? – How to aggregate workers’ answers in order to predict the location of a fault? So far we tried a set of predictors, e.g., difference between number of Yes and No answers (majority voting), number of Yes answers above a threshold, and ranking questions by the relative number of positive answers (e.g., “Yes, there is a fault here”). What if we also aggregate answers based on worker proficiency, type of question asked, size/complexity of the code fragment?
Where to start asking questions? – Our recent experiments showed that workers can locate faults within a faulty Java method. Considering that a failure involves the execution of many methods, which methods should we crowdsource first? Which program statements should we ask questions first?
When to ask questions? – As the crowd produces answers, can we decide which question should we ask next? What interdependencies between microtasks must be managed? How can a crowd make decisions? How can knowledge be presented to transient workers who do not know the right questions to ask.
If you are interested in any of these topics, please get in touch! Send an email to adrianoc at uci dot edu.
Team Members
- Christian M. Adriano
- Iago Moreira da Silva
Past Team Members
- Danilo Cardoso
- Nathan Martins